 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentFoX: LLM Agent-Guided Fusion with eXplainability for AI-Generated Image Detection
Mar 24, 2026The increasing realism of AI-Generated Images (AIGI) has created an urgent need for forensic tools capable of reliably distinguishing synthetic content from authentic imagery. Existing detectors are typically tailored to specific forgery artifacts--such as frequency-domain patterns or semantic inconsistencies--leading to specialized performance and, at times, conflicting judgments. To address these limitations, we present \textbf{AgentFoX}, a Large Language Model-driven framework that redefines AIGI detection as a dynamic, multi-phase analytical process. Our approach employs a quick-integration fusion mechanism guided by a curated knowledge base comprising calibrated Expert Profiles and contextual Clustering Profiles. During inference, the agent begins with high-level semantic assessment, then transitions to fine-grained, context-aware synthesis of signal-level expert evidence, resolving contradictions through structured reasoning. Instead of returning a coarse binary output, AgentFoX produces a detailed, human-readable forensic report that substantiates its verdict, enhancing interpretability and trustworthiness for real-world deployment. Beyond providing a novel detection solution, this work introduces a scalable agentic paradigm that facilitates intelligent integration of future and evolving forensic tools.
MPF-Net: Exposing High-Fidelity AI-Generated Video Forgeries via Hierarchical Manifold Deviation and Micro-Temporal Fluctuations
Jan 29, 2026With the rapid advancement of video generation models such as Veo and Wan, the visual quality of synthetic content has reached a level where macro-level semantic errors and temporal inconsistencies are no longer prominent. However, this does not imply that the distinction between real and cutting-edge high-fidelity fake is untraceable. We argue that AI-generated videos are essentially products of a manifold-fitting process rather than a physical recording. Consequently, the pixel composition logic of consecutive adjacent frames residual in AI videos exhibits a structured and homogenous characteristic. We term this phenomenon `Manifold Projection Fluctuations' (MPF). Driven by this insight, we propose a hierarchical dual-path framework that operates as a sequential filtering process. The first, the Static Manifold Deviation Branch, leverages the refined perceptual boundaries of Large-Scale Vision Foundation Models (VFMs) to capture residual spatial anomalies or physical violations that deviate from the natural real-world manifold (off-manifold). For the remaining high-fidelity videos that successfully reside on-manifold and evade spatial detection, we introduce the Micro-Temporal Fluctuation Branch as a secondary, fine-grained filter. By analyzing the structured MPF that persists even in visually perfect sequences, our framework ensures that forgeries are exposed regardless of whether they manifest as global real-world manifold deviations or subtle computational fingerprints.
Estimating Quality in Therapeutic Conversations: A Multi-Dimensional Natural Language Processing Framework
May 09, 2025



Engagement between client and therapist is a critical determinant of therapeutic success. We propose a multi-dimensional natural language processing (NLP) framework that objectively classifies engagement quality in counseling sessions based on textual transcripts. Using 253 motivational interviewing transcripts (150 high-quality, 103 low-quality), we extracted 42 features across four domains: conversational dynamics, semantic similarity as topic alignment, sentiment classification, and question detection. Classifiers, including Random Forest (RF), Cat-Boost, and Support Vector Machines (SVM), were hyperparameter tuned and trained using a stratified 5-fold cross-validation and evaluated on a holdout test set. On balanced (non-augmented) data, RF achieved the highest classification accuracy (76.7%), and SVM achieved the highest AUC (85.4%). After SMOTE-Tomek augmentation, performance improved significantly: RF achieved up to 88.9% accuracy, 90.0% F1-score, and 94.6% AUC, while SVM reached 81.1% accuracy, 83.1% F1-score, and 93.6% AUC. The augmented data results reflect the potential of the framework in future larger-scale applications. Feature contribution revealed conversational dynamics and semantic similarity between clients and therapists were among the top contributors, led by words uttered by the client (mean and standard deviation). The framework was robust across the original and augmented datasets and demonstrated consistent improvements in F1 scores and recall. While currently text-based, the framework supports future multimodal extensions (e.g., vocal tone, facial affect) for more holistic assessments. This work introduces a scalable, data-driven method for evaluating engagement quality of the therapy session, offering clinicians real-time feedback to enhance the quality of both virtual and in-person therapeutic interactions.
Understanding LLM Scientific Reasoning through Promptings and Model's Explanation on the Answers
May 02, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and problem-solving across various domains. However, their ability to perform complex, multi-step reasoning task-essential for applications in science, medicine, and law-remains an area of active investigation. This paper examines the reasoning capabilities of contemporary LLMs, analyzing their strengths, limitations, and potential for improvement. The study uses prompt engineering techniques on the Graduate-Level GoogleProof Q&A (GPQA) dataset to assess the scientific reasoning of GPT-4o. Five popular prompt engineering techniques and two tailored promptings were tested: baseline direct answer (zero-shot), chain-of-thought (CoT), zero-shot CoT, self-ask, self-consistency, decomposition, and multipath promptings. Our findings indicate that while LLMs exhibit emergent reasoning abilities, they often rely on pattern recognition rather than true logical inference, leading to inconsistencies in complex problem-solving. The results indicated that self-consistency outperformed the other prompt engineering technique with an accuracy of 52.99%, followed by direct answer (52.23%). Zero-shot CoT (50%) outperformed multipath (48.44%), decomposition (47.77%), self-ask (46.88%), and CoT (43.75%). Self-consistency performed the second worst in explaining the answers. Simple techniques such as direct answer, CoT, and zero-shot CoT have the best scientific reasoning. We propose a research agenda aimed at bridging these gaps by integrating structured reasoning frameworks, hybrid AI approaches, and human-in-the-loop methodologies. By critically evaluating the reasoning mechanisms of LLMs, this paper contributes to the ongoing discourse on the future of artificial general intelligence and the development of more robust, trustworthy AI systems.
FAN: Fatigue-Aware Network for Click-Through Rate Prediction in E-commerce Recommendation
Apr 10, 2023Since clicks usually contain heavy noise, increasing research efforts have been devoted to modeling implicit negative user behaviors (i.e., non-clicks). However, they either rely on explicit negative user behaviors (e.g., dislikes) or simply treat non-clicks as negative feedback, failing to learn negative user interests comprehensively. In such situations, users may experience fatigue because of seeing too many similar recommendations. In this paper, we propose Fatigue-Aware Network (FAN), a novel CTR model that directly perceives user fatigue from non-clicks. Specifically, we first apply Fourier Transformation to the time series generated from non-clicks, obtaining its frequency spectrum which contains comprehensive information about user fatigue. Then the frequency spectrum is modulated by category information of the target item to model the bias that both the upper bound of fatigue and users' patience is different for different categories. Moreover, a gating network is adopted to model the confidence of user fatigue and an auxiliary task is designed to guide the learning of user fatigue, so we can obtain a well-learned fatigue representation and combine it with user interests for the final CTR prediction. Experimental results on real-world datasets validate the superiority of FAN and online A/B tests also show FAN outperforms representative CTR models significantly.
Conversion Rate Prediction via Meta Learning in Small-Scale Recommendation Scenarios
Dec 27, 2021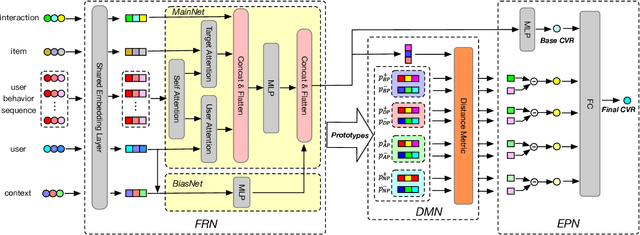
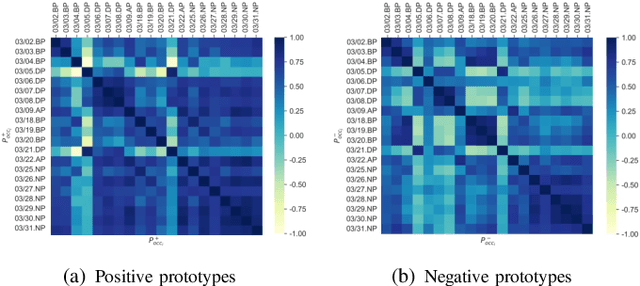
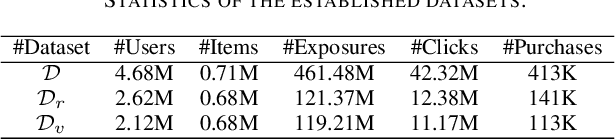
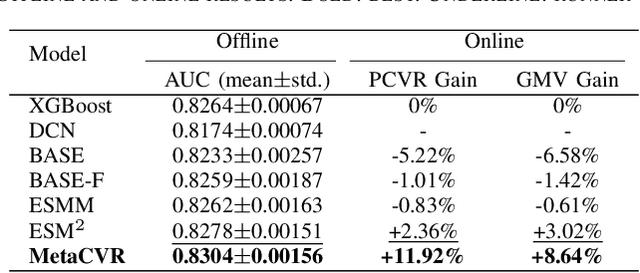
Different from large-scale platforms such as Taobao and Amazon, developing CVR models in small-scale recommendation scenarios is more challenging due to the severe Data Distribution Fluctuation (DDF) issue. DDF prevents existing CVR models from being effective since 1) several months of data are needed to train CVR models sufficiently in small scenarios, leading to considerable distribution discrepancy between training and online serving; and 2) e-commerce promotions have much more significant impacts on small scenarios, leading to distribution uncertainty of the upcoming time period. In this work, we propose a novel CVR method named MetaCVR from a perspective of meta learning to address the DDF issue. Firstly, a base CVR model which consists of a Feature Representation Network (FRN) and output layers is elaborately designed and trained sufficiently with samples across months. Then we treat time periods with different data distributions as different occasions and obtain positive and negative prototypes for each occasion using the corresponding samples and the pre-trained FRN. Subsequently, a Distance Metric Network (DMN) is devised to calculate the distance metrics between each sample and all prototypes to facilitate mitigating the distribution uncertainty. At last, we develop an Ensemble Prediction Network (EPN) which incorporates the output of FRN and DMN to make the final CVR prediction. In this stage, we freeze the FRN and train the DMN and EPN with samples from recent time period, therefore effectively easing the distribution discrepancy. To the best of our knowledge, this is the first study of CVR prediction targeting the DDF issue in small-scale recommendation scenarios. Experimental results on real-world datasets validate the superiority of our MetaCVR and online A/B test also shows our model achieves impressive gains of 11.92% on PCVR and 8.64% on GMV.
SAME: Scenario Adaptive Mixture-of-Experts for Promotion-Aware Click-Through Rate Prediction
Dec 27, 2021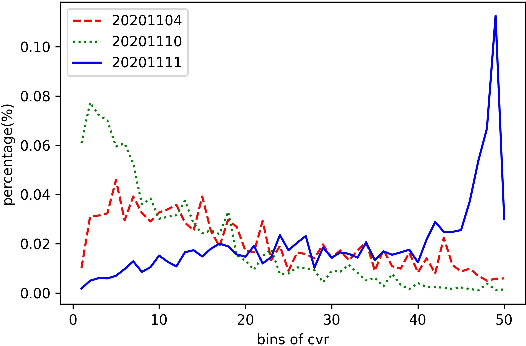
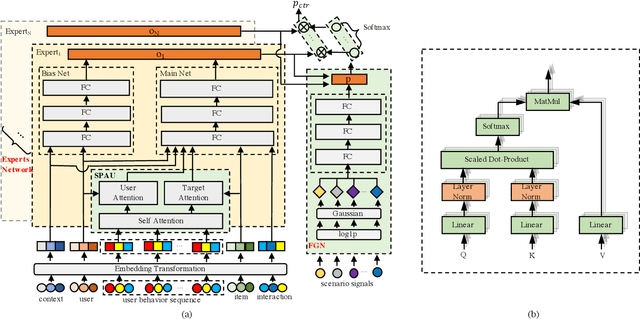
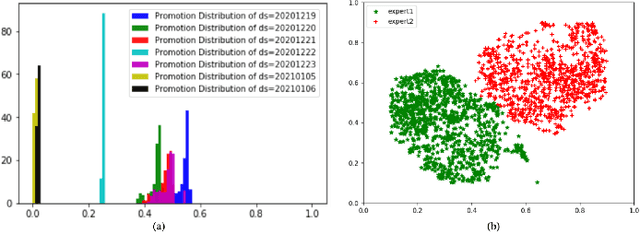
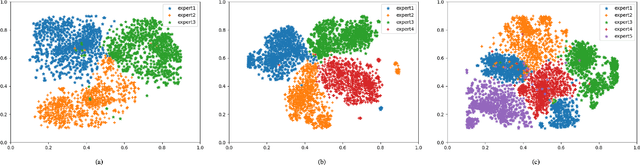
Promotions are becoming more important and prevalent in e-commerce platforms to attract customers and boost sales. However, Click-Through Rate (CTR) prediction methods in recommender systems are not able to handle such circumstances well since: 1) they can't generalize well to serving because the online data distribution is uncertain due to the potentially upcoming promotions; 2) without paying enough attention to scenario signals, they are incapable of learning different feature representation patterns which coexist in each scenario. In this work, we propose Scenario Adaptive Mixture-of-Experts (SAME), a simple yet effective model that serves both promotion and normal scenarios. Technically, it follows the idea of Mixture-of-Experts by adopting multiple experts to learn feature representations, which are modulated by a Feature Gated Network (FGN) via an attention mechanism. To obtain high-quality representations, we design a Stacked Parallel Attention Unit (SPAU) to help each expert better handle user behavior sequence. To tackle the distribution uncertainty, a set of scenario signals are elaborately devised from a perspective of time series prediction and fed into the FGN, whose output is concatenated with feature representation from each expert to learn the attention. Accordingly, a mixture of the feature representations is obtained scenario-adaptively and used for the final CTR prediction. In this way, each expert can learn a discriminative representation pattern. To the best of our knowledge, this is the first study for promotion-aware CTR prediction. Experimental results on real-world datasets validate the superiority of SAME. Online A/B test also shows SAME achieves significant gains of 3.58% on CTR and 5.94% on IPV during promotion periods as well as 3.93% and 6.57% in normal days, respectively.